DataStax
The following components support DataStax vector stores.
For more information, see the following:
1. Hidden parameters
2. Search results output
3. Vector store instances
4. Astra DB Serverless documentation
5. Hyper-Converged Database (HCD) documentation
Astra DB
The Astra DB component read and writes to Astra DB Serverless databases, using an instance of AstraDBVectorStore to call the Data API and DevOps API.
Astra DB parameters
| Name | Display Name | Info |
|---|---|---|
| token | Astra DB Application Token | Input parameter. An Astra application token with permission to access your vector database. Once the connection is verified, additional fields are populated with your existing databases and collections. If you want to create a database through this component, the application token must have Organization Administrator permissions. |
| environment | Environment | Input parameter. The environment for the Astra DB API endpoint. Always use prod. |
| database_name | Database | Input parameter. The name of the database that you want this component to connect to. Or, you can select New Database to create a new database, and then wait for the database to initialize. |
| keyspace | Keyspace | Input parameter. The keyspace in your database that contains the collection specified in collection_name. Default: default_keyspace. |
| collection_name | Collection | Input parameter. The name of the collection that you want to use with this flow. Or, select New Collection to create a new collection with limited configuration options. For proper configuration with embedding provider and search, use Astra Portal or Data API before configuring this component. |
| embedding_model | Embedding Model | Input parameter. Attach an Embedding Model component to generate embeddings. Only available if the specified collection doesn't have a vectorize integration. If a vectorize integration exists, the component automatically uses the collection's integrated model. |
| ingest_data | Ingest Data | Input parameter. The documents to load into the specified collection. |
| search_query | Search Query | Input parameter. The query string for vector search. |
| cache_vector_store | Cache Vector Store | Input parameter. Whether to cache the vector store in Robility flow memory for faster reads. Default: Enabled (true). |
| search_method | Search Method | Input parameter. The search methods to use, either Hybrid Search or Vector Search. Collection must support the chosen option. |
| reranker | Reranker | Input parameter. The re-ranker model to use for hybrid search, depending on collection configuration. Shows default even if collection doesn't support hybrid search. |
| lexical_terms | Lexical Terms | Input parameter. A space-separated string of keywords for hybrid search. Only available if the collection supports hybrid search. |
| number_of_results | Number of Search Results | Input parameter. The number of search results to return. Default: 4. |
| search_type | Search Type | Input parameter. The search type to use, either Similarity (default), Similarity with score threshold, and MMR (Max Marginal Relevance). |
| search_score_threshold | Search Score Threshold | Input parameter. Minimum similarity score threshold for vector search results with the Similarity with score threshold type. Default: 0. |
| advanced_search_filter | Search Metadata Filter | Input parameter. An optional dictionary of metadata filters to apply in addition to vector or hybrid search. |
| autodetect_collection | Autodetect Collection | Input parameter. Whether to automatically fetch a list of available collections after providing an application token and API endpoint. |
| content_field | Content Field | Input parameter. For writes, specifies the name of the field in documents containing text strings for generating embeddings. |
| deletion_field | Deletion Based On Field | Input parameter. When provided, documents in the target collection with metadata field values matching the input are deleted before new records are loaded. Useful for writes with upserts. |
| ignore_invalid_documents | Ignore Invalid Documents | Input parameter. Whether to ignore invalid documents during writes. If false, an error is raised for invalid documents. Default: Enabled (true). |
| astradb_vectorstore_kwargs | AstraDBVectorStore Parameters | Input parameter. An optional dictionary of additional parameters for the AstraDBVectorStore instance. For more information, see Vector store instances. |
The Astra DB component supports the Data API’s hybrid search feature. Hybrid search performs a vector similarity search and a lexical search, compares the results of both searches, and then returns the most relevant results overall.
To use hybrid search through the Astra DB component, do the following:
1. Use the Data API to create a collection that supports hybrid search if you haven’t already created one.
Although you can create a collection through the Astra DB component, you have more control and insight into the collection settings when using the Data API for this operation.
2. Create a flow based on the Hybrid Search RAG template, which includes an Astra DB component that is pre-configured for hybrid search.
3. In the Language Model components, add your OpenAI API key.
4. Delete the Language Model component that is connected to the Structured Output component’s Input Message port, and then connect the Chat Input component to that port.
5. Configure the Astra DB vector store component:
a. Enter your Astra DB application token.
b. In the Database field, select your database.
c. In the Collection field, select your collection with hybrid search enabled.
Once you select a collection that supports hybrid search, the other parameters automatically update to allow hybrid search options.
6. In the component’s header menu, click Controls, find the Lexical Terms field, enable the Show toggle, and then click Close.
7. Connect the first Parser component’s Parsed Text output to the Astra DB component’s Lexical Terms input. This input only appears after connecting a collection that support hybrid search with reranking.
8. Click the Structured Output component to expose the component’s header menu, click Controls, find the Format Instructions row, click Expand, and then replace the prompt with the following text:
You are a database query planner that takes a user’s requests and then converts to a search against the subject matter in question.
You should convert the query into:
a. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams.
b. A question to use as the basis for a QA embedding engine.
Avoid common keywords associated with the user’s subject matter.
a. Click Finish Editing, and then click Close to save your changes to the component.
b. Open the Playground and then enter a natural language question that you would ask about your database.
In this example, your input is sent to both the Astra DB and Structured Output components:
9. The input sent directly to the Astra DB component’s Search Query port is used as a string for similarity search. An embedding is generated from the query string using the collection’s Astra DB vectorize integration.
10. The input sent to the Structured Output component is processed by the Structured Output, Language Model, and Parser components to extract space-separated keywords used for the lexical search portion of the hybrid search.
The complete hybrid search query is executed against your database using the Data API’s find_and_rerank command. The API’s response is output as a DataFrame that is transformed into a text string Message by another Parser component. Finally, the Chat Output component prints the Message response to the Playground.
11. Optional: Exit the Playground, and then click Inspect Output on each individual component to understand how lexical keywords were constructed and view the raw response from the Data API. This is helpful for debugging flows where a certain component isn’t receiving input as expected from another component.
12. Structured Output component: The output is the Data object produced by applying the output schema to the LLM’s response to the input message and format instructions. The following example is based on the aforementioned instructions for keyword extraction:
a. Keywords: features, data, attributes, characteristics
b. Question: What characteristics can be identified in my data?
13. Parser component: The output is the string of keywords extracted from the structured output Data and then used as lexical terms for the hybrid search.
a. Astra DB component: The output is the DataFrame containing the results of the hybrid search as returned by the Data API.
Astra DB Graph
The Astra DB Graph component uses a AstraDBGraphVectorStore instance for graph traversal and graph-based document retrieval in an Astra DB collection. It also supports writing to the vector store.
Astra DB Graph parameters
| Name | Display Name | Info |
|---|---|---|
| token | Astra DB Application Token | Input parameter. An Astra application token with permission to access your vector database. Once the connection is verified, additional fields are populated with your existing databases and collections. If you want to create a database through this component, the application token must have Organization Administrator permissions. |
| api_endpoint | API Endpoint | Input parameter. Your database's API endpoint. |
| keyspace | Keyspace | Input parameter. The keyspace in your database that contains the collection specified in collection_name. Default: default_keyspace. |
| collection_name | Collection | Input parameter. The name of the collection that you want to use with this flow. For write operations, if a matching collection doesn't exist, a new one is created. |
| metadata_incoming_links_key | Metadata Incoming Links Key | Input parameter. The metadata key for the incoming links in the vector store. |
| ingest_data | Ingest Data | Input parameter. Records to load into the vector store. Only relevant for writes. |
| search_input | Search Query | Input parameter. Query string for similarity search. Only relevant for reads. |
| cache_vector_store | Cache Vector Store | Input parameter. Whether to cache the vector store in Robility flow memory for faster reads. Default: Enabled (true). |
| embedding_model | Embedding Model | Input parameter. Attach an Embedding Model component to generate embeddings. If the collection has a vectorize integration, don't attach an Embedding Model component. |
| metric | Metric | Input parameter. The metrics to use for similarity search calculations, either cosine (default), dot_product, or euclidean. This is a collection setting. |
| batch_size | Batch Size | Input parameter. Optional number of records to process in a single batch. |
| bulk_insert_batch_concurrency | Bulk Insert Batch Concurrency | Input parameter. Optional concurrency level for bulk write operations. |
| bulk_insert_overwrite_concurrency | Bulk Insert Overwrite Concurrency | Input parameter. Optional concurrency level for bulk write operations that allow upserts (overwriting existing records). |
| bulk_delete_concurrency | Bulk Delete Concurrency | Input parameter. Optional concurrency level for bulk delete operations. |
| setup_mode | Setup Mode | Input parameter. Configuration mode for setting up the vector store, either Sync (default) or Off. |
| pre_delete_collection | Pre Delete Collection | Input parameter. Whether to delete the collection before creating a new one. Default: Disabled (false). |
| metadata_indexing_include | Metadata Indexing Include | Input parameter. List of metadata fields to index if enabling selective indexing when creating a collection. Applies only to new collections. |
| metadata_indexing_exclude | Metadata Indexing Exclude | Input parameter. List of metadata fields to exclude from indexing if enabling selective indexing when creating a collection. Applies only to new collections. |
| collection_indexing_policy | Collection Indexing Policy | Input parameter. Dictionary to define indexing policy for new collections, allowing subfields or complex definitions. |
| number_of_results | Number of Results | Input parameter. Number of search results to return. Default: 4. Only relevant to reads. |
| search_type | Search Type | Input parameter. Search type to use: Similarity, Similarity with score threshold, MMR, Graph Traversal, or MMR Graph Traversal (default). Only relevant to reads. |
| search_score_threshold | Search Score Threshold | Input parameter. Minimum similarity score threshold for search results if using Similarity with score threshold. Default: 0. |
| search_filter | Search Metadata Filter | Input parameter. Optional dictionary of metadata filters to apply in addition to vector search. |
Graph RAG
The Graph RAG component uses an instance of GraphRetriever for Graph RAG traversal enabling graph-based document retrieval in an Astra DB vector store. For more information, see the DataStax Graph RAG documentation.
Points to note
This component was meant as a Graph RAG extension for the Astra DB vector store component. However, the Astra DB Graph component includes both the vector store connection and Graph RAG functionality.
Graph RAG parameters
| Name | Display Name | Info |
|---|---|---|
| embedding_model | Embedding Model | Input parameter. Specify the embedding model to use. Not required if the connected vector store has a vectorize integration. |
| vector_store | Vector Store Connection | Input parameter. A vector_store instance inherited from an Astra DB component's Vector Store Connection output. |
| edge_definition | Edge Definition | Input parameter. Edge definition for the graph traversal. |
| strategy | Traversal Strategies | Input parameter. The strategy to use for graph traversal. Strategy options are dynamically loaded from available strategies. |
| search_query | Search Query | Input parameter. The query to search for in the vector store. |
| graphrag_strategy_kwargs | Strategy Parameters | Input parameter. Optional dictionary of additional parameters for the retrieval strategy. |
| search_results | Search Results or DataFrame | Output parameter. The results of the graph-based document retrieval as a list of Data objects or as a tabular DataFrame. You can set the desired output type near the component's output port. |
Hyper-Converged Database (HCD)
The Hyper-Converged Database (HCD) component uses your cluster’s the Data API server to read and write to an HCD vector store. Because the underlying functions call the Data API, which originated from Astra DB, the component uses an instance of AstraDBVectorStore.
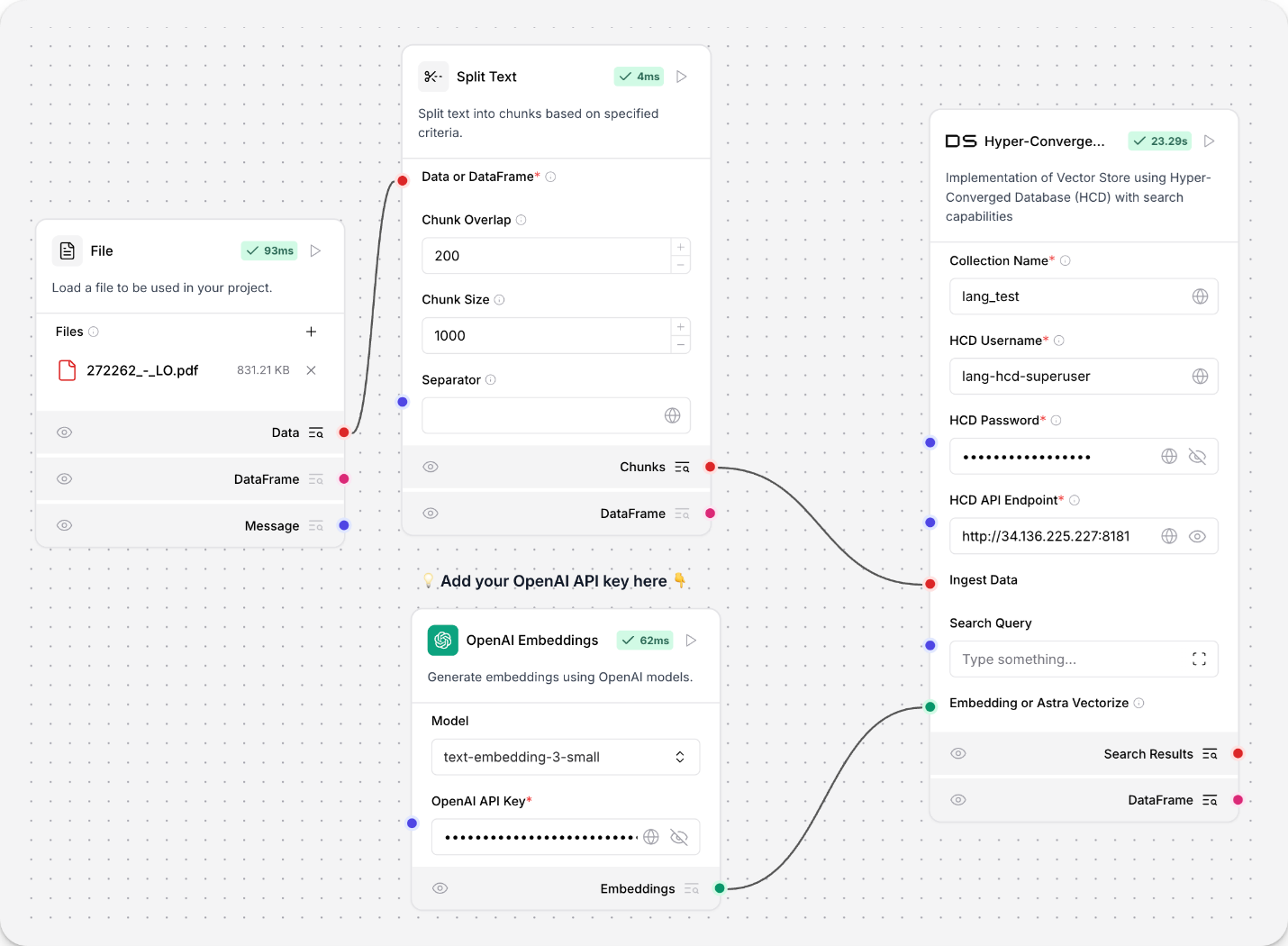
For more information about using the Data API with an HCD deployment, see Get started with the Data API in HCD 1.2.
HCD parameters
| Name | Display Name | Info |
|---|---|---|
| collection_name | Collection Name | Input parameter. The name of a vector store collection in HCD. For write operations, if the collection doesn't exist, then a new one is created. Required. |
| username | HCD Username | Input parameter. Username for authenticating to your HCD deployment. Default: hcd-superuser. Required. |
| password | HCD Password | Input parameter. Password for authenticating to your HCD deployment. Required. |
| api_endpoint | HCD API Endpoint | Input parameter. Your deployment's HCD Data API endpoint, formatted as http[s]://**CLUSTER_HOST**:**GATEWAY_PORT**. Required. |
| ingest_data | Ingest Data | Input parameter. Records to load into the vector store. Only relevant for writes. |
| search_input | Search Input | Input parameter. Query string for similarity search. Only relevant for reads. |
| namespace | Namespace | Input parameter. The namespace in HCD that contains or will contain the collection specified in collection_name. Default: default_namespace. |
| ca_certificate | CA Certificate | Input parameter. Optional CA certificate for TLS connections to HCD. |
| metric | Metric | Input parameter. The metrics to use for similarity search calculations, either cosine, dot_product, or euclidean. Collection setting. Leave unset to use collection's metric if calling an existing collection. |
| batch_size | Batch Size | Input parameter. Optional number of records to process in a single batch. |
| bulk_insert_batch_concurrency | Bulk Insert Batch Concurrency | Input parameter. Optional concurrency level for bulk write operations. |
| bulk_insert_overwrite_concurrency | Bulk Insert Overwrite Concurrency | Input parameter. Optional concurrency level for bulk write operations that allow upserts (overwriting existing records). |
| bulk_delete_concurrency | Bulk Delete Concurrency | Input parameter. Optional concurrency level for bulk delete operations. |
| setup_mode | Setup Mode | Input parameter. Configuration mode for setting up the vector store, either Sync (default), Async, or Off. |
| pre_delete_collection | Pre Delete Collection | Input parameter. Whether to delete the collection before creating a new one. |
| metadata_indexing_include | Metadata Indexing Include | Input parameter. List of metadata fields to index if enabling selective indexing for new collections. Only one *_indexing_* parameter can be set per collection. |
| metadata_indexing_exclude | Metadata Indexing Exclude | Input parameter. List of metadata fields to exclude from indexing if enabling selective indexing for new collections. Only one *_indexing_* parameter can be set per collection. |
| collection_indexing_policy | Collection Indexing Policy | Input parameter. Dictionary defining the indexing policy for new collections. Only one *_indexing_* parameter can be set per collection. Used for subfields or complex indexing definitions. |
| embedding | Embedding or Astra Vectorize | Input parameter. The embedding model to use by attaching an Embedding Model component. Vectorize integrations not supported. |
| number_of_results | Number of Results | Input parameter. Number of search results to return. Default: 4. Only relevant to reads. |
| search_type | Search Type | Input parameter. Search type to use, either Similarity (default), Similarity with score threshold, or MMR (Max Marginal Relevance). Only relevant to reads. |
| search_score_threshold | Search Score Threshold | Input parameter. Minimum similarity score threshold for search results if search_type is Similarity with score threshold. Default: 0. |
| search_filter | Search Metadata Filter | Input parameter. Optional dictionary of metadata filters to apply in addition to vector search. |
